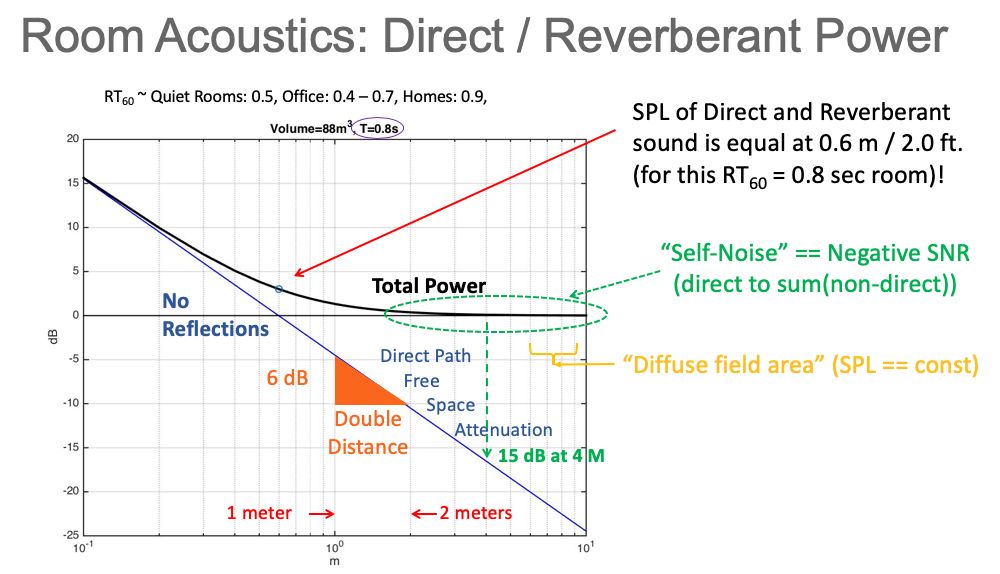
In acoustics, the distance at which the sound pressure (measured power) of the direct sound (D) and the reverberant sound (R) are equal is called the “critical distance.”
For most reasonably sized rooms this distance is only two or three feet. At distances longer than the critical distance the power of the reverberations (the sum of all the reflections) is greater than the direct sound! That is, the direct-sound to non-direct-sound ratio is negative.
Figure 1 shows the power of the direct sound (D, in blue) and the total power ([D + R], in black) for a room
volume of 88 cubic meters and a RT60 reverberation time of 0.8 seconds (the amount of time for the power to
decay 60 dB after release of stimulus) as a function of distance from the source (horizontal axis).
Note that the total power flattens out to a constant far enough away from the source in what is
called “the diffuse field” in acoustics – at these distances the power in the direct sound is negligible.
If we consider the non-direct-sound power to be a self-noise component (not strictly true for speech as early reflection energy increases speech intelligibility), humans often need to decode in negative signal-to-noise ratio (SNR) distances from the source. Our human auditory system routinely decodes in “negative SNR” settings such as the so-called “cocktail party” situations, where room noise (typically other conversations) is louder than the person we wish to hear. It is well known that humans can decode speech down to about -15 dB SNR (for references, Google “Speech Intelligibility Index”). The human ability to decode in negative SNR is due to: 1) the fact that speech signals are highly redundant (signal is encoded with special redundancy), and 2) the human auditory system itself is designed to exploit the redundancy (allowing it to decode in negative SNR settings).
Successful information transfer in reverberant rooms is no different than speech, the best systems use “redundant encoding” for the transmitted signal (item 1 above) and decoding tuned to the characteristics of the transmitted signal (item 2 above).
In contrast to the human ability to decode in negative SNR, virtually all non-spread spectrum-based transmission systems require positive SNR to decode properly. This is why room-based information transmission is difficult using traditional communications techniques such as tones and the usual forms of modulation; the “information carrying signal” (the direct signal or a more dominant reflection) must have power greater than the non-information carrying components (noise or other reflections). A SNR of 12 dB or more is typically required for most traditional non-spread spectrum communications schemes. This fact alone puts these non-spread spectrum techniques at a deficit relative to human auditory function by over 20 dB!
It is also impossible to “hide” the information-carrying signals when using non-spread spectrum techniques due to the need for positive SNR (this is a requirement for some stenographic applications). One can easily find the information-carrying signal using those techniques using spectral tools (e.g., spectrograms). We shall see below that we can “bury” the information carrying signal under existing signals via spread-spectrum techniques and thus make those signals invisible to casual observation. Indeed, this “signal hiding” attribute is why many military communications use spread spectrum for covert communications.
Given a transmitter (typically a speaker in the “sending system”) and a receiver (typically a microphone at a “user endpoint”) one can measure a room impulse response (RIR) that characterizes the room transfer function from the transmitter to the receiver. Whenever you change the location of either transmitter or receiver, you get a different RIR.
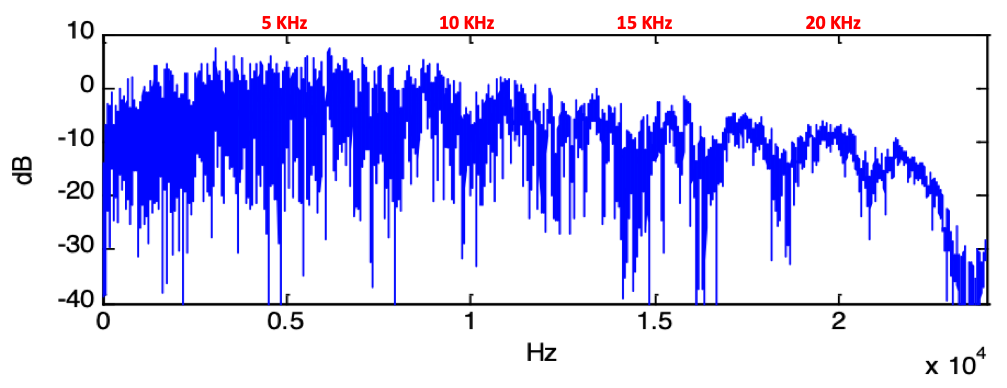
Figure 2 shows the magnitude response of a typical RIR between a transmitter and receiver in
a conference room.
It is clearly seen that that there are many frequencies where a signal at a particular frequency
is nulled (cancelled by more than 30 dB) by its reflections.
Moreover, it is also seen that there are variations in magnitude of 10 dB or more between any two
arbitrarily chosen frequencies.
This makes the design of a system using one or a few tones difficult – one or more of the tones
may not survive and those that do often have vastly different magnitudes (as well as phases/delays).
To further complicate matters, many speakers (as well as microphone pickups) are directional.
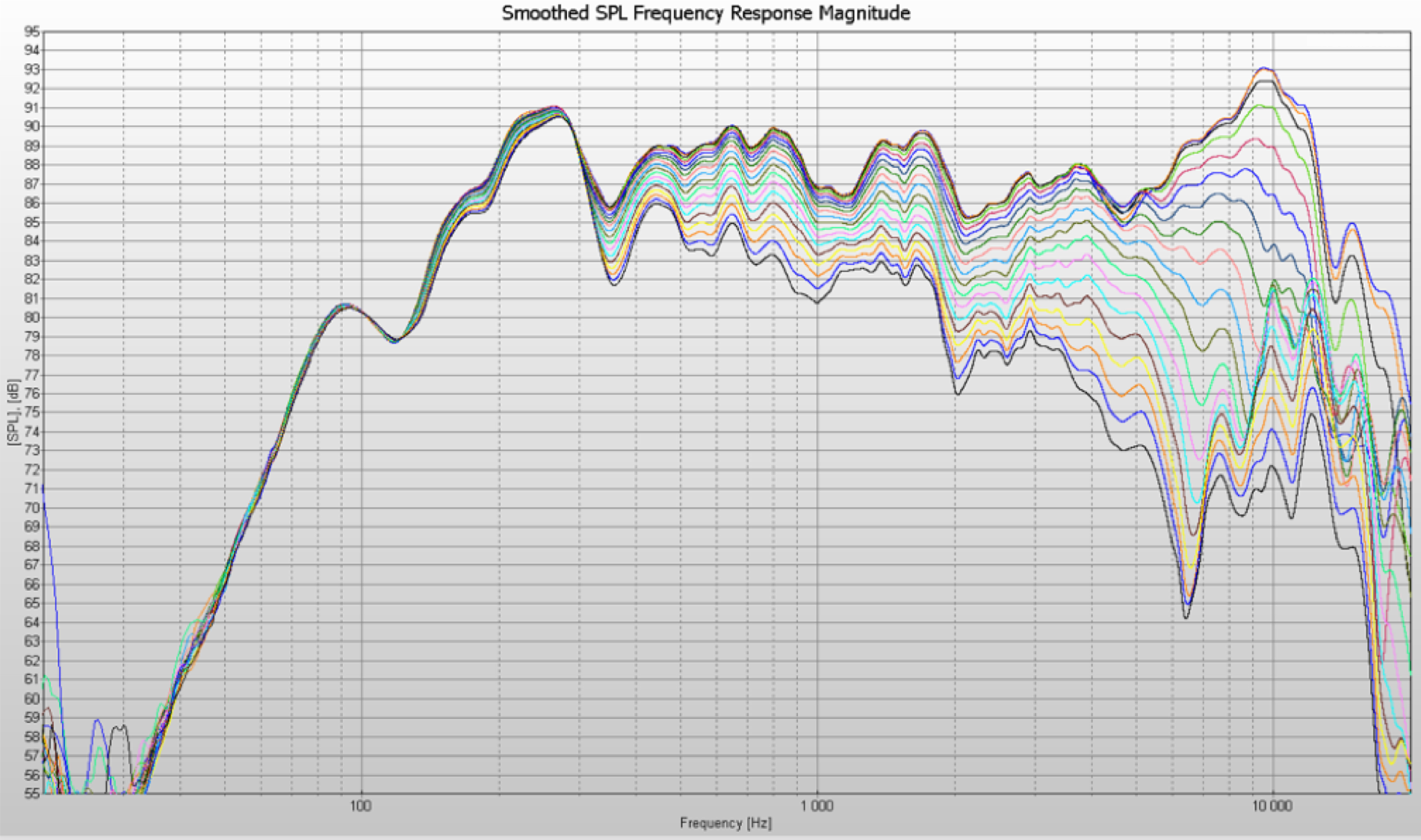
Figure 3 shows the magnitude response of a speaker as a function of how “off axis” the microphone
is from the “0 degree” on-axis speaker response in free space (not in a reverberant room).
Thus, the magnitude response is made even more uncertain and variable dependent on directionality
to the sound source (and microphone pickup directionality as well).
These variabilities present formidable constraints on system design.
Moving one of the endpoints results in a different RIR with similar characteristics, but one
in which the nulls move to different frequencies.
This effect increases with increasing frequencies: the movement of the receiving endpoint by
as little as a centimeter moves the nulls of higher frequency components significantly.
This movement causes great difficulty for tone-based designs, as small endpoint movement
can drastically change the magnitude/phases of the tones (this effect is
called “fading” in communications).
We now see that room reverberation creates a severe multi-path acoustic environment
and slowly moving endpoints worsen the situation via fading.
These effects together conspire to make the use of tone-based techniques even more difficult.
[Difficult, but not impossible. One can use a multiplicity of tones and use special encoding (e.g., an error-correcting code) such that only a subset of them need to survive to convey information. AcousticComms can help with such a design even though a spread-spectrum based design is superior in many dimensions.]
There is not room here for a thesis on spread spectrum design, but cornerstone in the theory is the
concept of “spreading” and the tradeoff of this spreading and a so-called “spread spectrum gain”.
The result is that some portion of the signal can be lost (i.e., signal energy in frequency nulls) and
that as long as enough survives (i.e., energy not in nulls) the signal can still be successfully decoded.
The theory is well developed in communications literature, but heretofore has not been applied for
information transfer in room acoustic environments.
If we assume a reverberant room environment (and potentially a slowly moving endpoint as above), the
channel will have nulls/valleys that are unpredictable in location and can move.
Designing a system with fixed tones will be difficult.
However, designing a spread spectrum system in which the information carrying signal is
spread – but some of that signal power can be “lost” in the nulls wherever they happen to be – is
of great benefit.
If we design the spread spectrum gain to account for the worst-case signal power loss, the received
signal can be decoded without error!
Indeed, with enough gain we can even place the information-carrying signal under the ambient
energy (other sounds or general noise) and still decode without error!
A non-spread spectrum system simply cannot do this due to the need for positive SNR decoding.
In short, the use of spread spectrum for the reverberant room environment is ideal in that you don’t
need to know a priori where the nulls are precisely – you only need to know that some transmitted signal
energy will be lost due to them.
And if you design your system well, you can overcome that loss!
In contrast, non-spread spectrum techniques need to test/measure the acoustic environment and
then use heuristics or coding and/or other techniques (e.g., equalization) to adapt the system
to the environment. As we have seen above, such a system is very brittle - moving the transmitter or
receiver just a little bit can ruin the transmittion due to the channel changing dynamically.
Finally, we can use the spread spectrum gain to lower the transmit power via the
well-known “spreading vs gain” tradeoff - every dB of spread spectrum gain can be used to
lower transmit power levels.
In contrast, non-spread spectrum designs must have transmitted power levels such that the received
signal power is higher than the ambient noise (to achieve positive SNR at decoder) at all possible decode
locations in the room.
For large room volumes the spread spectrum design can be set 20 dB or more lower than the non-spread
spectrum system – a very significant reduction in the necessary transmit power.
Despite the fact that humans communicate in reverberant rooms such as conference rooms and
classrooms, the design of a robust information transmission for general use in these rooms
is difficult for the reasons outlined above.
One can design simple, non-spread spectrum designs via heuristics and/or other techniques that can work
most of the time – but may not work robustly because of the technical challenges presented by
reverberant rooms, acoustic I/O (speakers and microphones) and unanticipated noise sources.
Spread spectrum transmission designs can overcome virtually all of the difficulty of
non-spread spectrum transmission – at lower transmit power, with more robustness and with
the potential of hiding the signal (with enough spread spectrum gain).
We note here that spread spectrum-based systems “lock onto” the dominant signal - be it the direct signal or a
dominant reflection – and as long as enough signal power survives the information can be decoded.
This is important for military use of spread-spectrum, as the dominant signal is almost always
a reflection.
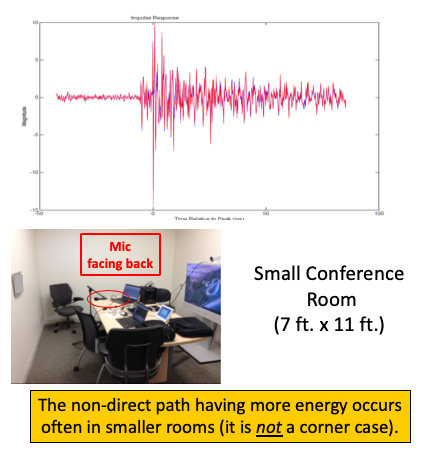
Figure 4 shows an example of such a case where the transmitting endpoint is the Telepresence
System and the receiving microphone has a beam pickup pattern that faces the rear wall.
Note that this situation is not uncommon for a PC at that location, as their microphones are
usually pointed away from the source.
Here we see that the dominant energy is a reflection off the back wall and that the direct
path actually arrives about 12 milliseconds before the dominant reflection.
It is the domanant reflection that is decoded at the receiver - as it has more received power
than the direct signal.
Additionally, existing spread spectrum theory also provides us bounds on the tradeoffs
possible (spread vs gain) as well as theoretical capacity bounds (for a given signal
spreading bandwidth) for decoding at negative SNR.
Excepting Cisco Systems proximity pairing systems previously mentioned
(US Patent 10,003,377 is base patent), the industry
has thus far not applied spread spectrum technology to the challenge of information transmission
in reverberant rooms.
There are many more systems and applications that can benefit from spread spectrum design
for information transmission in reverberant rooms.
Different applications and systems can exploit this acoustic Direct Sequence Spread Spectrum technology.
AcousticComms can help with both spread spectrum and non-spread spectrum designs that accommodate
different constraints and applications.
Michael A. Ramalho
Moving Endpoints: A Multi-Path Environment with "Fading"
Room Reverberation + Moving Endpoints = Difficult Communications Design
Spread Spectrum Best for a Fading and Severe Multi-Path Acoustic Room Environment
Summary
How AccousticComms Can Help
Last Modified on :
May 16, 2025
Page Owner :
Michael A. Ramalho, Ph.D.